Cascading failures and the impossibility of scheduling team lunches
An illustrated guide on the importance of implementing timeouts and other features to increase system reliability

Jean-Mark is an articulate, customer-focused, visionary with extensive industry experience encompassing front and back end development in all phases of software development. He lives "outside the box" in pursuit of architectural elegance and relevant, tangible solutions. He is a strong believer that team empowerment fosters genius and is versed at working solo.
Introduction
In this article, I'm going to talk about the impact of cascading failures on a system and how we can mitigate the impact using timeouts, retries and circuit breakers. When a failure happens in one of your systems or components, you don't want that failure propagating, or cascading to other areas. You must control the blast radius, or everything will go up in flames. Ideally, you want to ensure that your components absorb shocks and strains and don't provide a pathway for propagation. One uncontained fault can jeopardize your system's availability and reliability. We can use timeouts, circuit breakers, and other techniques to reduce the impact.
It's lunchtime!
To illustrate the problem, we'll consider the task of scheduling team lunch for a rather busy set of colleagues. Let's assume everybody is working remotely and tends to have a life, which gets in the way of team initiatives. This makes scheduling a rather interesting adventure. Nobody pays attention to the polls in Slack to decide on a time for lunch, so we have to resort to calling everyone manually. For our consideration, let's assume I called the restaurant and was fortunate enough to get a patient representative who waited while I called my other team members to book.
Have a look at the diagram below. Hopefully, it looks familiar. It's a trace graph! Each box represents some action that's happening. The first box represents the duration of my call to the restaurant. The boxes in the next line represent each co-worker I'm calling in an attempt to schedule the team lunch. Each box below represents the life commitments that make scheduling a time-consuming affair. Let's take a closer look!
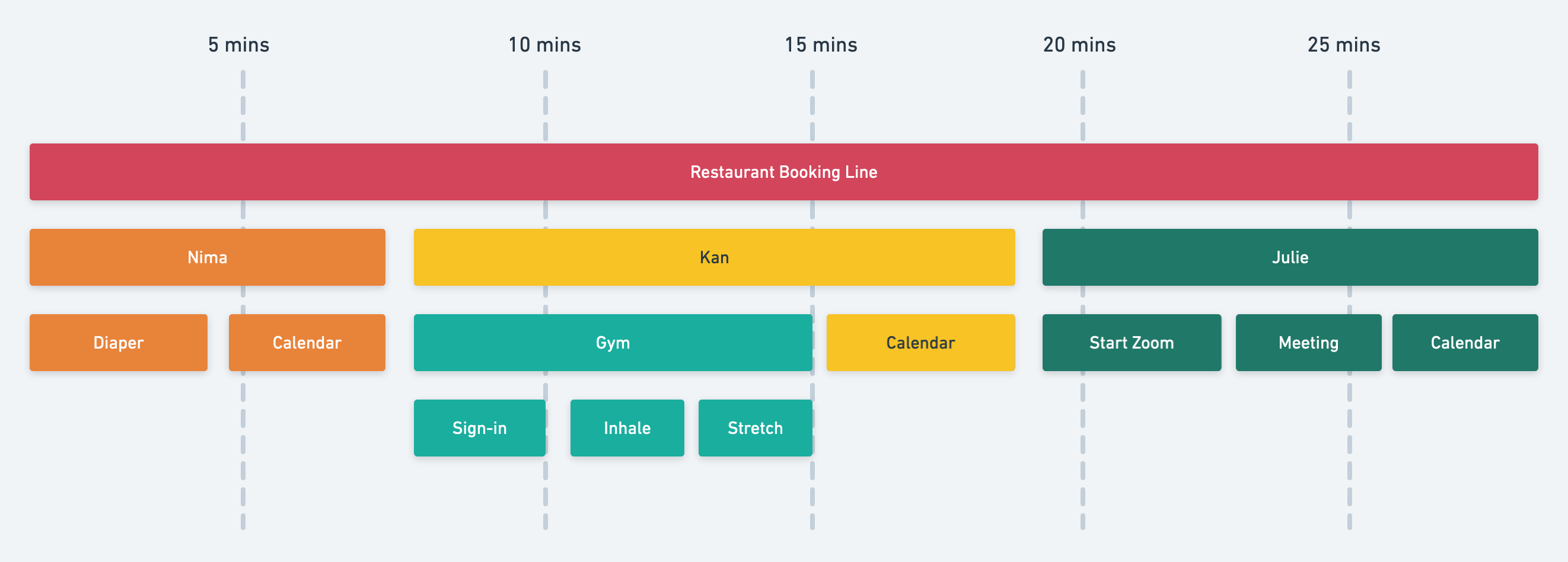
So I called the restaurant and asked them to hold while I connected with my colleagues and confirmed. First up, I got a Pakistani colleague we'll call Nima. He has a beautiful baby girl. When I called he just happened to be in the middle of a diaper change. Yikes. After surgically removing the diaper and installing a clean one, it took him a few more minutes to get back to his computer and check his calendar. He's free! Next up, Kan, a health-conscious teammate who faithfully and consistently goes to the gym once or twice every couple of months. Just my luck! Gym time just happens to be now. I had to wait until he signed in and did his intensive workout session consisting of inhaling and stretching. 15 minutes in, he's able to get back to his computer and check his schedule, he's free! Finally, let's check in with Julie. It's almost 20 minutes and I can hear the receptionist on the line getting impatient. She's having issues getting Zoom started, and she's about to head into a quick meeting. Close to the half-hour mark, Julie confirms that she too is free! Overjoyed, the receptionist books us in and terminates the call.
Phew... that only took 30 minutes. The receptionist had to wait for me to connect with all my colleagues. All of them had different things on their plate and were unable to respond immediately. In many cases, the stuff on their plate (not talking about Nima's plate... obviously) also took time. Now, let's look at a rather extreme example, then see what we can learn from this illustration.
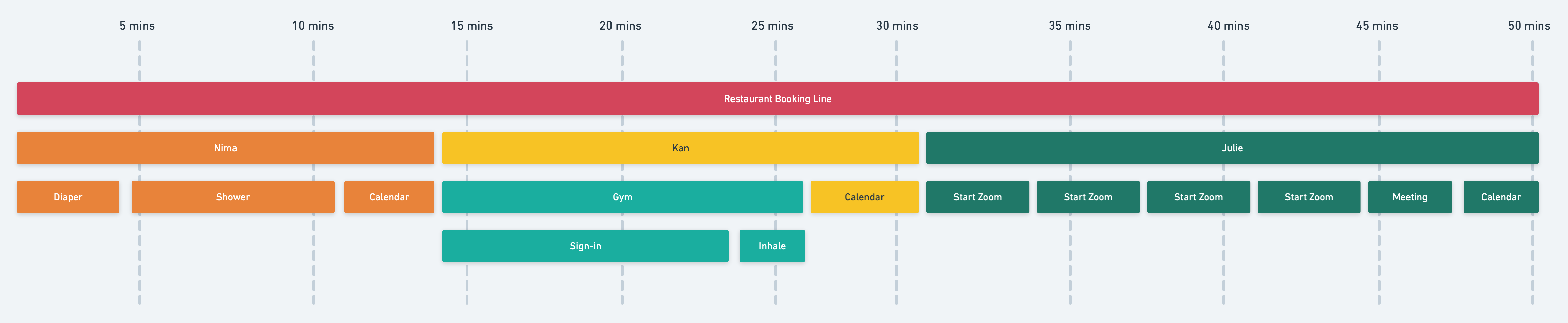
So this time, let's say Nima's surgery didn't go as planned and he decided to take a shower.
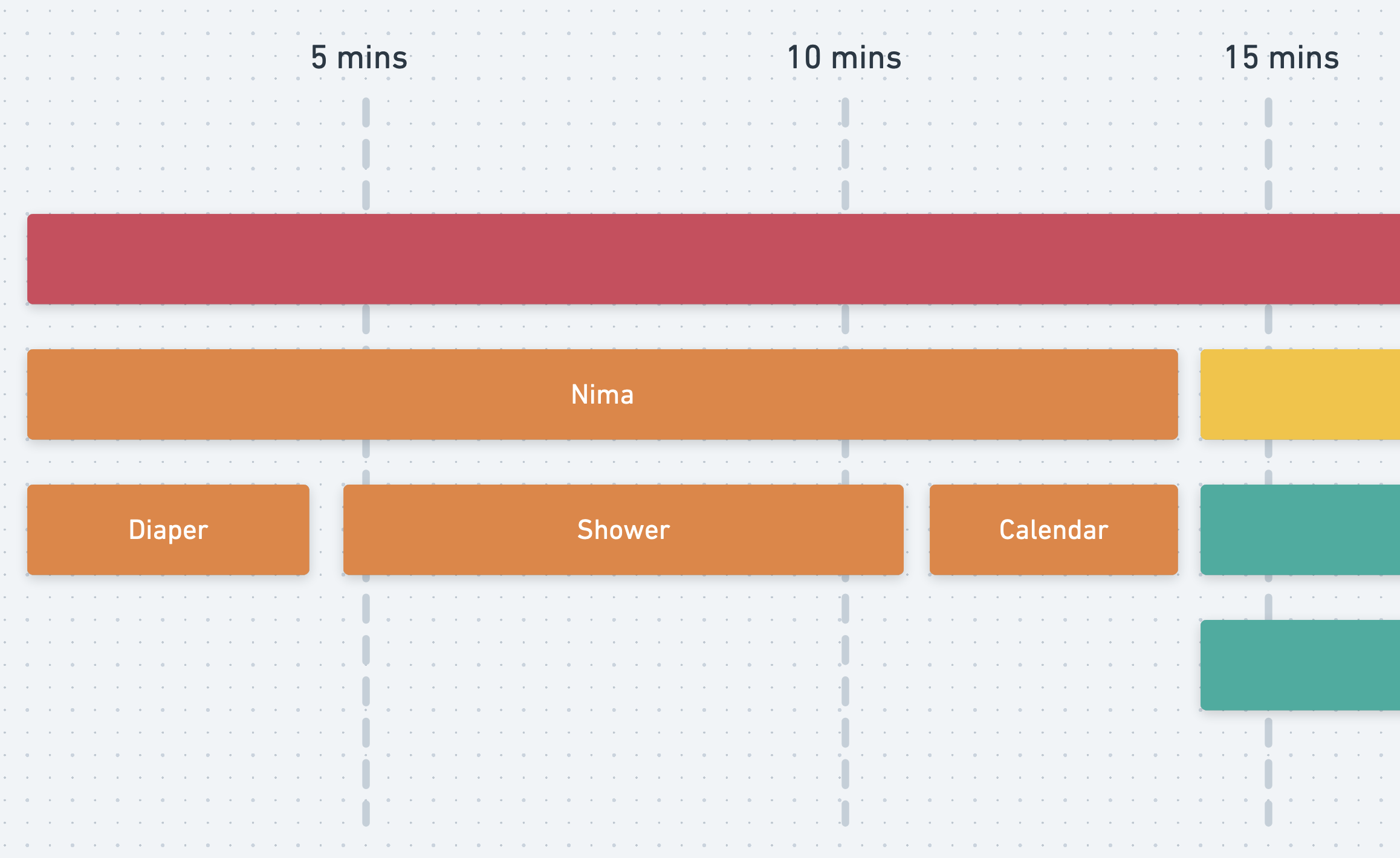
I had to wait 15 minutes just to have him check his calendar and confirm his availability. Then, let's say Kan ran into a long line at the gym, so it took him forever to sign in.
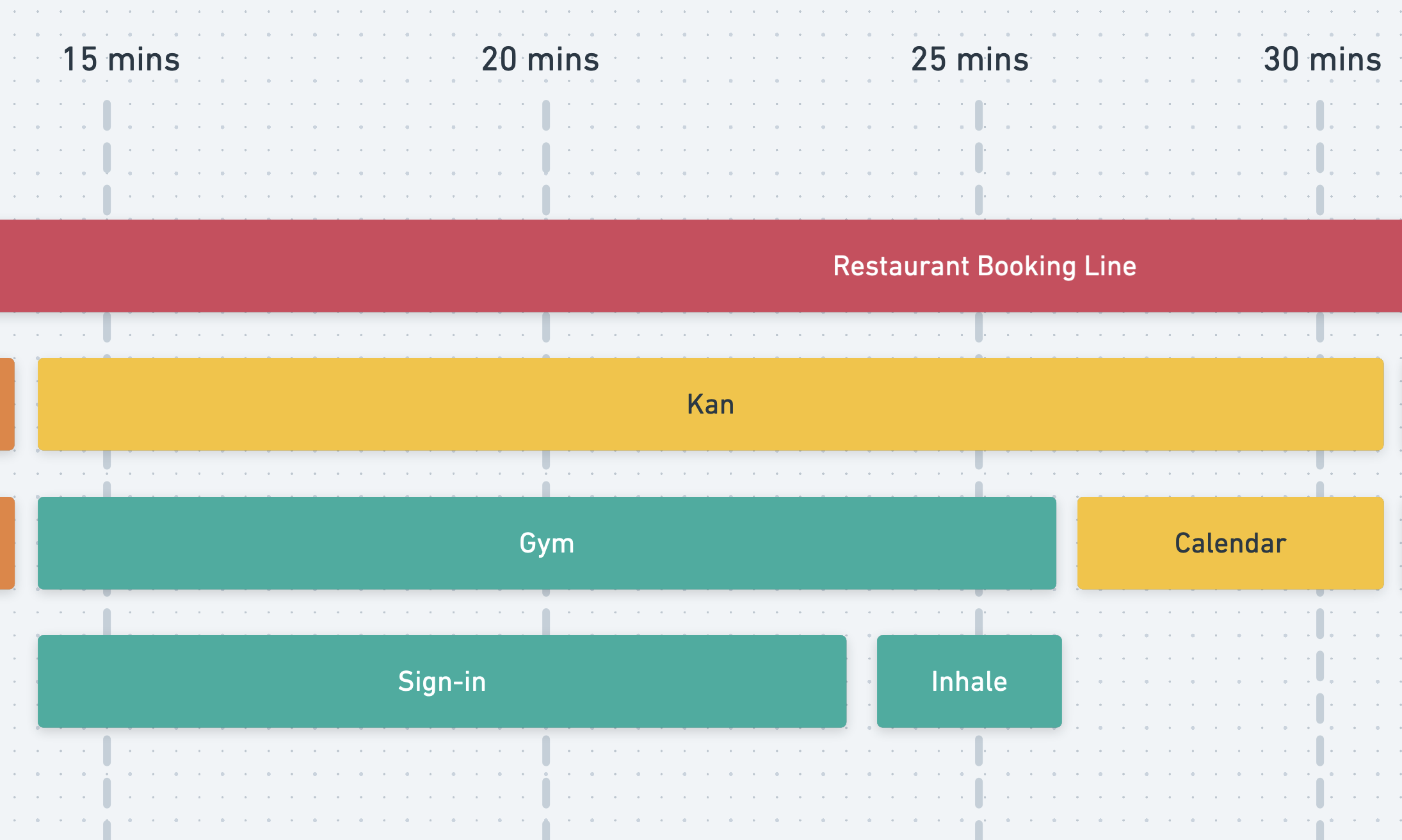
After waiting nearly 10 minutes, I managed to convince him to cut his routine short and just inhale a couple of times while he was heading back to the car to get his laptop. It's 30 mins already.
Then to top things off, I call Julie only to find out she's having intense Zoom issues and has to keep restarting Zoom.
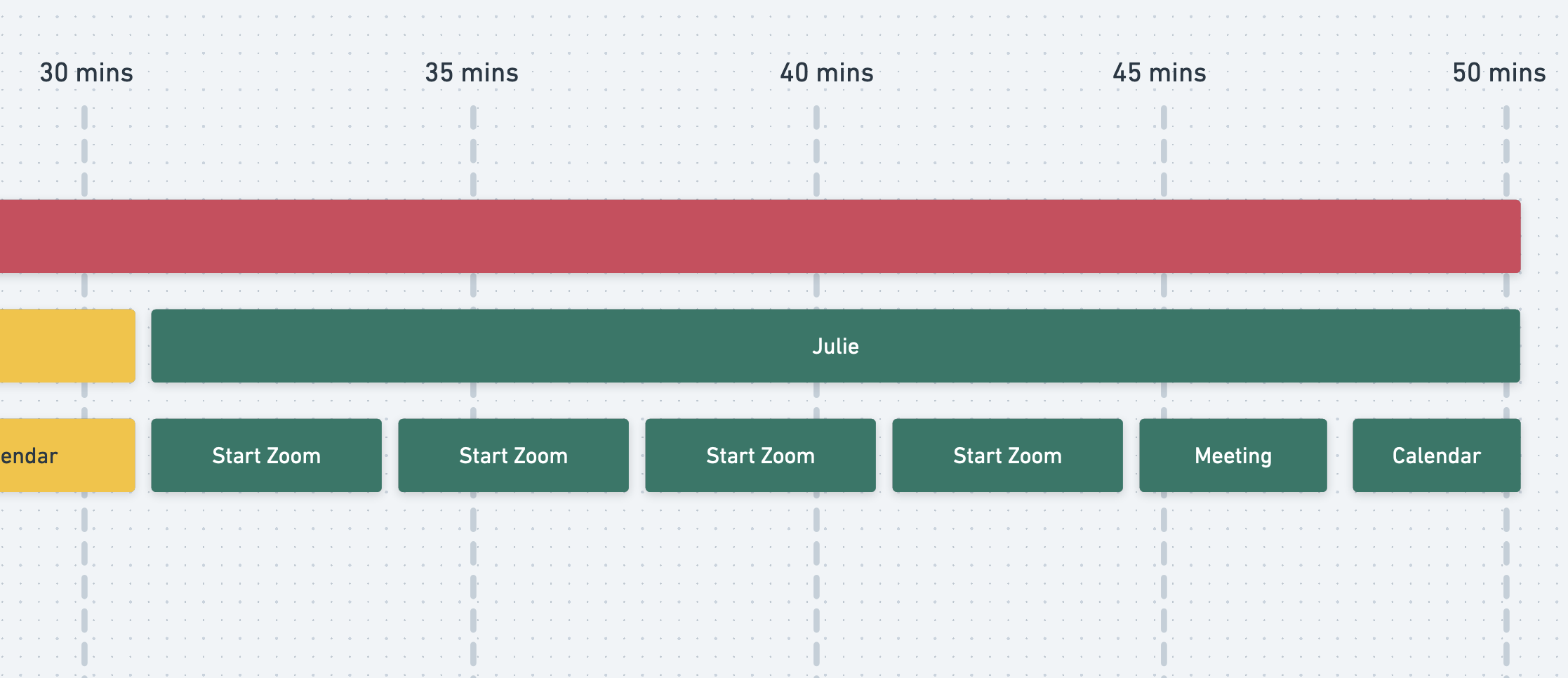
It's another 15-minute wait before she's able to check her calendar. With almost an hour elapsed, I can guarantee the restaurant won't be taking any future calls from me.
There must be a better way
As we could see in the illustration above, all the different tasks that my colleagues were doing extended the timeline for the call. In the last example, I spent an entire hour trying to schedule a simple team lunch. Because there was a lineup at the gym, Kan had to wait, which meant I had to wait, which meant the restaurant customer service rep had to wait too.
This is of course isn't a great situation. The poor customer service rep at the restaurant shouldn't have had to wait an hour for me to book time at the restaurant. That's an hour they could be serving other customers, generating revenue, and working towards Employee of the Month. Instead, that rep has to explain to their boss how my colleague's diaper surgery caused a significant loss of revenue to the restaurant. Or, how a potential customer's inhaling took up 20 minutes of their time.
This sounds pretty odd, but every time we call a remote service without proper boundaries we're doing the same thing. Often, as part of fulfilling some requests, our systems call out to remote dependencies (caches, databases, queues, internal services, and external third parties). Every dependency has the potential to induce undue strain on our system. AWS could be having an outage, or another service we depend on could be experiencing some degradation. Without proper controls in place, one problem can dramatically impact our system's availability and reliability. In this world where microservices are quite common, it's typical to have a dizzying web of dependencies involved in the fulfillment of a simple request. Uncontrolled calls can cause significant contention and impact many of the services in the web.
Let's look at how we improve.
Issue a deadline - timeouts, retries, backoff, and circuit breakers
Timeouts
The first concept that's critical to containing the blast radius is timeouts. If we effectively gave everyone on the call a deadline -- say a minute or two, we can control the maximum length of the call. If I have three colleagues and I'm only willing to wait 2 minutes for each person to respond, then the call shouldn't go too far beyond 6 minutes. This would reduce the wildly varying possibility that the poor employee could be waiting anywhere between a few minutes to hours for me to complete my booking. This also contains the impact of any one person's tasks on our scheduling. If we have a cutoff then Nima's surgeries won't bubble up, causing me to wait, which pushes the restaurant employee further from that Employee of the Month Award.
In the age of microservices, transient failures and prolonged outages are quite common. One system may experience an influx of requests they weren't prepared to manage. Or, someone could have rolled out a faulty change at a third party that caused our requests to take longer, or fail. Any and all of these changes can cascade if they're not controlled. When we use timeouts, we dampen the impact of these stresses and strains. If the cache is experiencing some degradation, applying a timeout means we wait up to a specified maximum then we abandon the call. This ensures that a dependency failure (e.g. a cache failing) doesn't impact our consumers, or our consumers' consumers, and so on. By stopping the propagation we ensure this fault doesn't spread across the web of microservices and bring others down.
Retries and Backoff
Another approach that's closely related to timeouts is Retries. If I called and realized that my colleague is busy, I could wait until the deadline was exceeded and then offer to call back in a few minutes. Chances are they might be less tied up in a few minutes. We can take a similar approach with our systems. If we reach out to a dependency and don't get a reply before the timeout, we can retry after a short delay. Typically that retry could be a few milliseconds. We can also set a maximum number of retries. Many dependency issues are transient. In such cases, retrying after a short delay increases the likelihood of a successful response. Placing a cap on the number of retries guarantees that prolonged issues don't cascade. If there's an outage, retries might likely fail too. Setting the right number of retries gives us the right balance between making our consumers wait, or failing early with an error.
When we timeout and then delay for a fixed interval, it could compound the problem if our dependency is under heavy load. Imagine some dependency we're trying to reach is buckling under heavy load. If every caller is timing out and then retrying at a similar interval, the system could end up getting surges called a Thundering Herd. Effectively, everyone tries to get in, waits for a short delay, then everyone tries to get in again (roughly) at the same time. That complicates recovery for the target system. The system doesn't get to recover properly due to surges hitting it by clients retrying at similar intervals. Instead of using a fixed interval, we can randomize the delay before retrying. This helps breaks the synchronicity with other clients and effectively reduces the net load on the target server.
Taking this strategy one step further, we can increase the time we're willing to wait with each retry. In particular, we can increase the maximum random delay exponentially. This allows us to provide more room for the target system to recover. If the problem is indeed transient, allowing the dependency some breathing room might be just what it needs to recover from whatever degradation is occurring. This is widely known as Random Exponential Backoff. We're backing off after each request and calculating a random delay that we're willing to wait. On each retry, we increase the maximum possible time exponentially. This can really help in reducing the load on a target system. Often load from consumers compounds issues a system faces, so using Random Exponential Backoff helps to alleviate some of the load, allowing a system to recover.
Circuit Breakers
Finally, if I noticed I'd been unsuccessful in getting to one of my colleagues, I could make a decision to stop calling. Instead of continuously retrying, I could effectively postpone all attempts to call until after I've surpassed a fixed number of retries. This is another common strategy that helps to prevent failures from cascading. By making a firm decision to stop forwarding requests to a suboptimal dependency, we're preventing any degradation from impacting any of our consumers. Instead of continuing to wait, which means our consumers have to wait, we can just fail gracefully, and earlier with an appropriate error. Unfortunately, this does often mean loss of functionality for our customers, but the upside is the maintenance of availability and reliability. By choosing not to forward requests to a borked dependency, we are removing lots of potential contention on the network that could impact many other areas of our service. We're ensuring one bad apple doesn't spoil the entire bunch.
Conclusion
And that's a wrap! I hope you enjoyed this post about cascading failures and how we can mitigate them in our systems. If we're not careful failures can cascade and have a sustained impact on our systems and impact our customers. The discussed strategies help us combat these issues while providing a graceful experience for our customers! Thanks for stopping by!
I'd love to hear some of your stories about how these strategies worked for you! Let's chat!




