Order matters - making a compound index 50x faster
A story of how we made a compound index 50x faster by re-organizing the fields

Jean-Mark is an articulate, customer-focused, visionary with extensive industry experience encompassing front and back end development in all phases of software development. He lives "outside the box" in pursuit of architectural elegance and relevant, tangible solutions. He is a strong believer that team empowerment fosters genius and is versed at working solo.
Introduction
Today I’ll talk about an endpoint that initially performed under 30ms, then crept up to ~500ms after a couple months. Our investigation revealed that a query, powered by a compound index was responsible for the elevated latency. We explored a few different ideas attempting to reduce the latency. Eventually we made an interesting discovery about the order and purpose of the index fields. Ultimately, we reduced the latency to sub 10 ms after the tweaks. Keep reading to hear about the journey.
The Problem
We had an asynchronous worker that actioned critical subscription lifecycle events (e.g. creation, cancellation, updates) obtained from a third-party. It provisioned our customers with feature access after they purchased a subscription, upgraded or cancelled their plan. The worker pulls the latest unprocessed events of certain event types from our database and processed them. The underlying query pulled a list of events, filtered them by status and event type, then ordered them. This query dominated the endpoint latency, and got slower over time. We wanted to keep it low-latency to ensure customer changes were quickly reflected in our system. For example, when a customer completed a purchase, we needed our system to process that event so we could provision them with the purchased features. And thus… we began our quest to reduce the latency!
A little more on the query…
The table in question had a few million rows… not crazy big. We were filtering by two fields (status and event_type), and sorting by one (occurred_at). The status field had one of of four values (e.g. processed, unprocessed) and event_type had ~100 different values (e.g. SUBSCRIPTION_CREATED, SUBSCRIPTION_CANCELLED). occurred_at being a timestamp, was fairly unique, having a few million values. Naturally, when you hear “suboptimal query”, you immediately wonder if there’s an index in place. We did have one, it was just insufficient for some reason. We had a compound index on occurred_at and event_type, in that order. That means our index was first partitioned by occurred_at, then by event_type. So… we were partitioning the index by the field we ordered the data by (occurred_at), then by event_type. Again… the index was partitioned first by the field we were ordering the data by, then by the filter field. You’ll want to remember that detail. We’ll come back to it.
So… an index existed… containing two of the three fields we were querying for.
Let’s extend our index coverage
Our first instinct was to extend our index coverage — add the missing field to the index. The index only had occurred_at and event_type (in that order), but our query was filtering by event_type and the status, then ordering by occurred_at. We talked with EXPLAIN and it seemed to suggest we’d get an incremental improvement. Hoping EXPLAIN was mistaken, we quickly coded the migration to remove the old index and one with all three fields (occurred_at, event_type and status — in that order).
Let’s get a visual on the disappointment that followed…
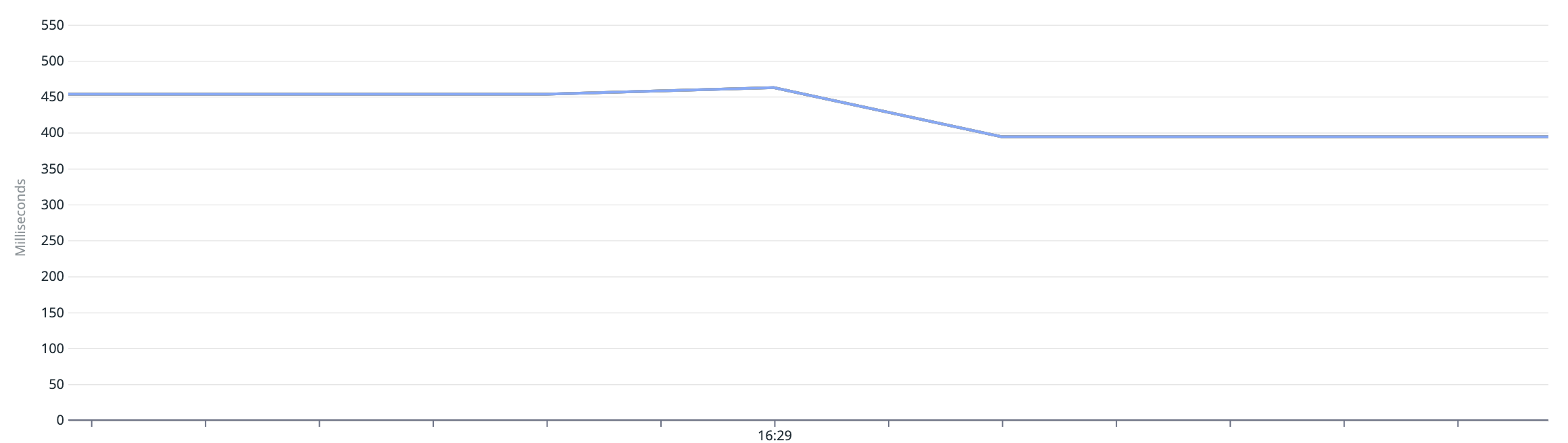
We were hoping for a nose dive in the latency… but we only got a mild improvement on the latency. It was now performing ~50ms faster. How underwhelming…
Adding more intentionality to our index order
The Postgres docs explain how index field order affects query performance and efficiency. The index field order determines the number of records that must be scanned. Scanning more records takes more time. An efficient index will drastically reduce the number of records that need to be scanned. On the other hand, an inefficient index increases query latency because Postgres is busy scanning the entire index. It’s not as bad as a table scan, but it’s definitely suboptimal.
Here’s a quote from the docs…
the index is most efficient when there are constraints on the leading (leftmost) columns
https://www.postgresql.org/docs/current/indexes-multicolumn.html
So Postgres wants your left most index fields to narrow the search space, or reduce the records Postgres has to scan to match the query criteria. In other words… Postgres wants your left most fields to eliminate parts of the tree that must be searched for values.
The key question here is… if we’re partitioning by occurred_at first, then by event_type and status — is that the most optimal structure?
Let’s consider this visual…
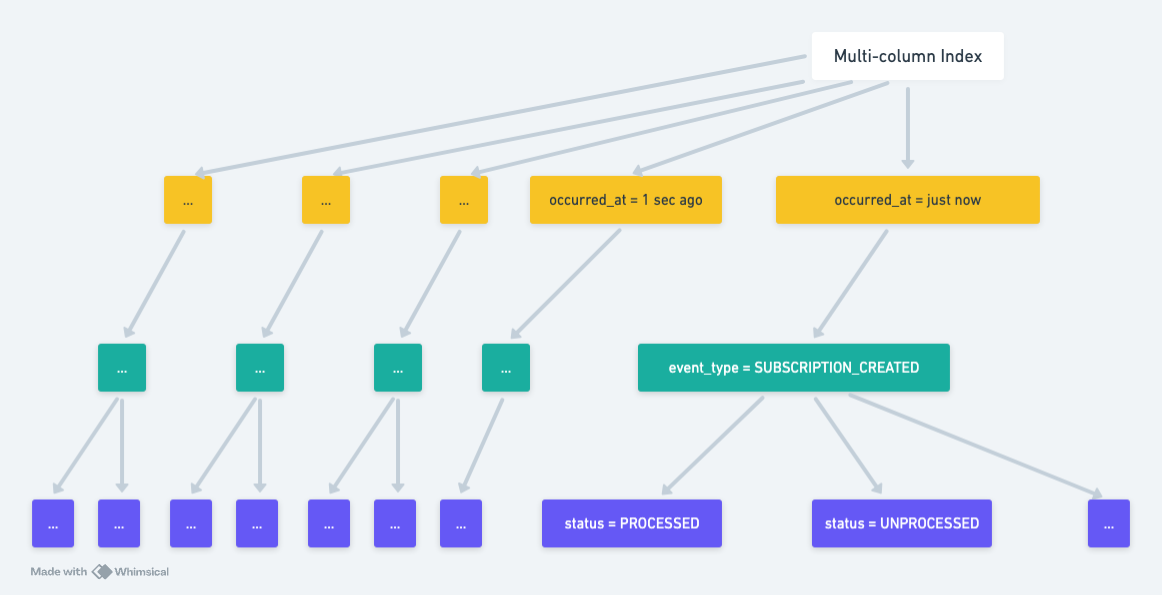
The diagram above explains why Postgres was doing a lot of work given our current index structure. Our index didn’t partition the tree and reduce the search space for Postgres at all. In order to filter by event_type and status we were asking Postgres to check every occurred_at value! After checking each value for occurred_at, it could then partition the tree, only looking at the event_type and statuses we’re interested in. So Postgres was doing a lot of work because, we were asking it to check millions of occurred_at values. This doesn’t sub-divide the tree in a way that reduces the branches Postgres has to search.
Let’s help Postgres out
Understanding this, we decided to put the fields we were filtering by first. By putting the status first, we could focus only on unprocessed events — that should reduce the search space considerably. Then, the tree can be further partitioned by the event_type. Again we’re only interested in a handful of those (~12 out of the 100). That should also further subdivide the tree. Then finally, we still wanted occurred_at in our index, because we wanted those values to be sorted, so we could retrieve the earliest first.
Let’s look at a visual of the updated index structure…
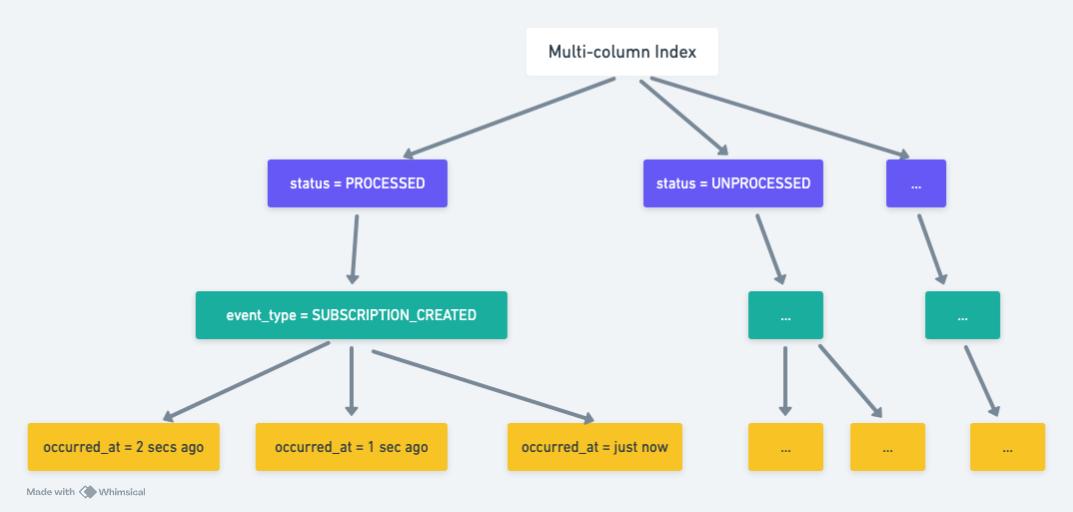
From the diagram above you can image how happier Postgres should be. It could descend down the left-most branch of the tree into to only scan our subscriptions where status = processed. Then, it’d do the same thing, only considering the subtree where our event_types match the ones we’re interested in. Then finally, since occurred_at also exists in the index, it can pick up those values too! This feels a lot lighter for Postgres… in theory… but.. will it work?
Does Postgres like our theory?
So… back to production we went with our new theory wrapped up in a new migration restructuring the index. Well.. no sooner than we deployed we started to see the latency jumping off a cliff — heading full speed ahead to sub 10ms!!!!
Let’s bring the graph to put a visual to the answer…
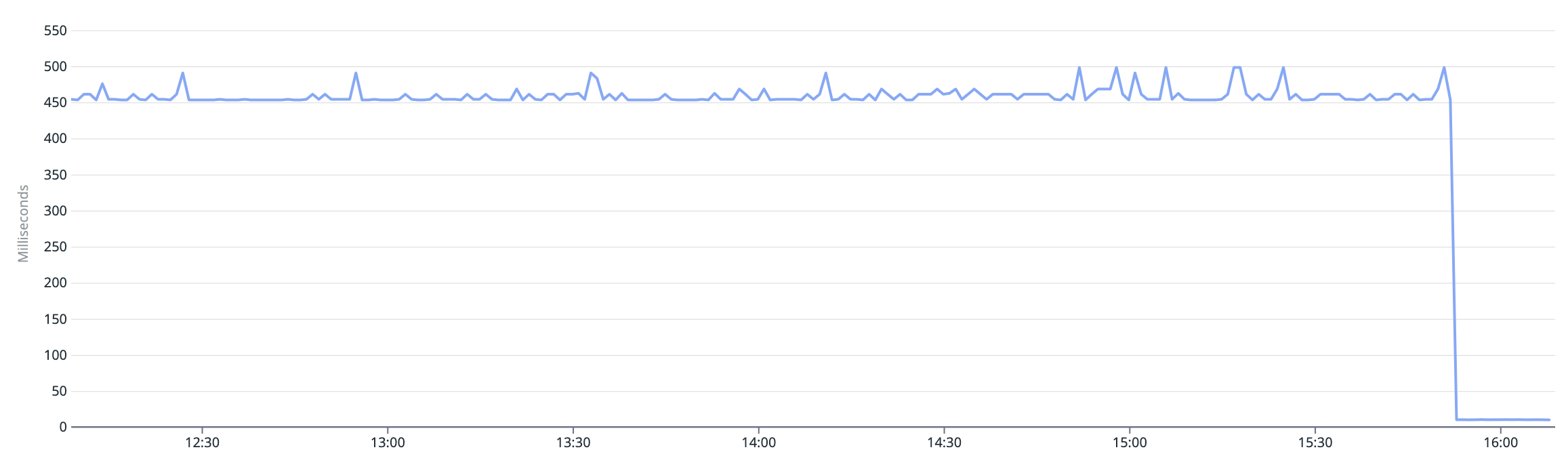
YES! YES! YES! Can you tell? It was unusually satisfying. Seeing your application aspire to be a sky diver without a parachute is extremely gratifying. All while learning more about the intricacies of Postgres and how its internal data structures work.
Conclusion
In conclusion, our journey to reduce the latency of this endpoint was both enlightening and rewarding. A better understanding of how Postgres handles compound indexes and the importance of field ordering, helped us significantly optimize our query. By restructuring the index to prioritize our filter fields first, we effectively reduced the search space, increasing Postgres’ efficiency. The result? A drastic improvement in performance, with the endpoint now performing under 10ms. And that’s a wrap! I’d love to hear your stories about your struggles and victories with Postgres.
Thanks for stopping by!



